Evaluate Accuracy
Introduction
Evals in PromptQL provide a systematic way to test and evaluate the accuracy of your domain-specific agent against custom prompts and datasets. Think of evals like quality checks for your agent: they help you measure how well PromptQL understands your business and delivers accurate, reliable results.
Whether you're testing a new version of your assistant, comparing different approaches, or validating changes to your data setup, evals give you the tools to make confident decisions. Since PromptQL works with immutable builds—meaning each update creates a new, testable version—you can consistently measure the impact of your changes and roll back if needed.
Core Components
Creating Test Cases
Each eval consists of four key components:
| Field | Description |
|---|---|
| Prompt | The specific question or instruction you want to test against your PromptQL agent |
| Tags | Key-value pairs to organize and filter related test cases (e.g., "category: customer-support", "priority: high") |
| Eval Criteria | Your success criteria, such as "Completeness, Efficiency, Readability" or custom scoring rubrics |
| Business Impact | A description of why this test matters to your business operations |
Use tags to create logical groupings of your test cases:
- Regression tests -
type: regressionto ensure existing functionality doesn't break with updates - Edge case testing -
category: edge-caseto validate behavior with unusual or boundary conditions - Performance benchmarks -
benchmark: performanceto compare different model configurations or approaches - Domain-specific tests -
domain: financeordomain: healthcareto test industry-specific knowledge and behavior
Evaluation Process
PromptQL's evaluation workflow is designed around your defined criteria and business context. After creating your eval items, you can run them against your agent to assess how well the responses meet your requirements. The evaluation process considers business-critical factors—like factual accuracy, data completeness, and domain-specific requirements—ensuring that results align with your specific use case and quality standards.
Guide
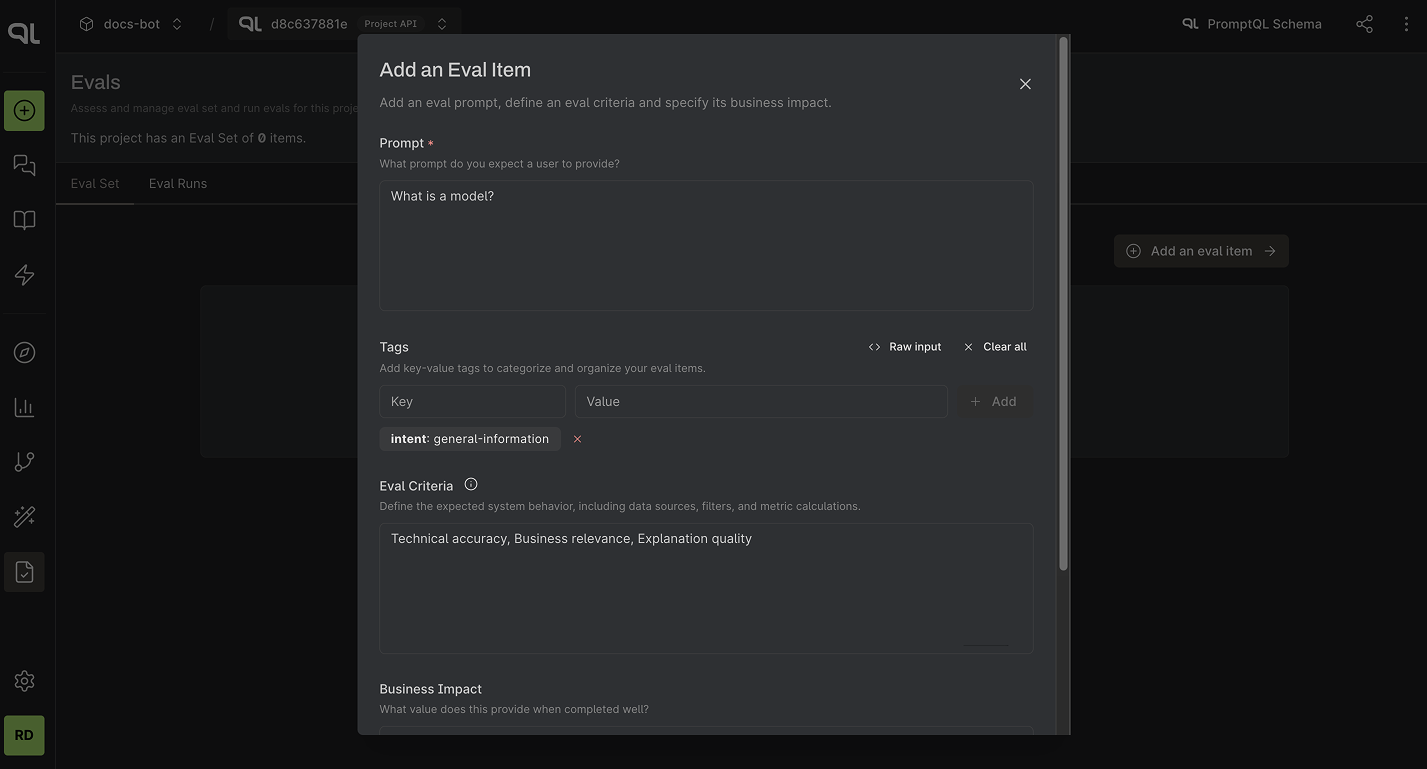
Step 1. Create an Eval Item
Go to the Evals tab in the console and click on Add an Eval Item. Add the prompt, tags, Eval Criteria, and
Business Impact fields.
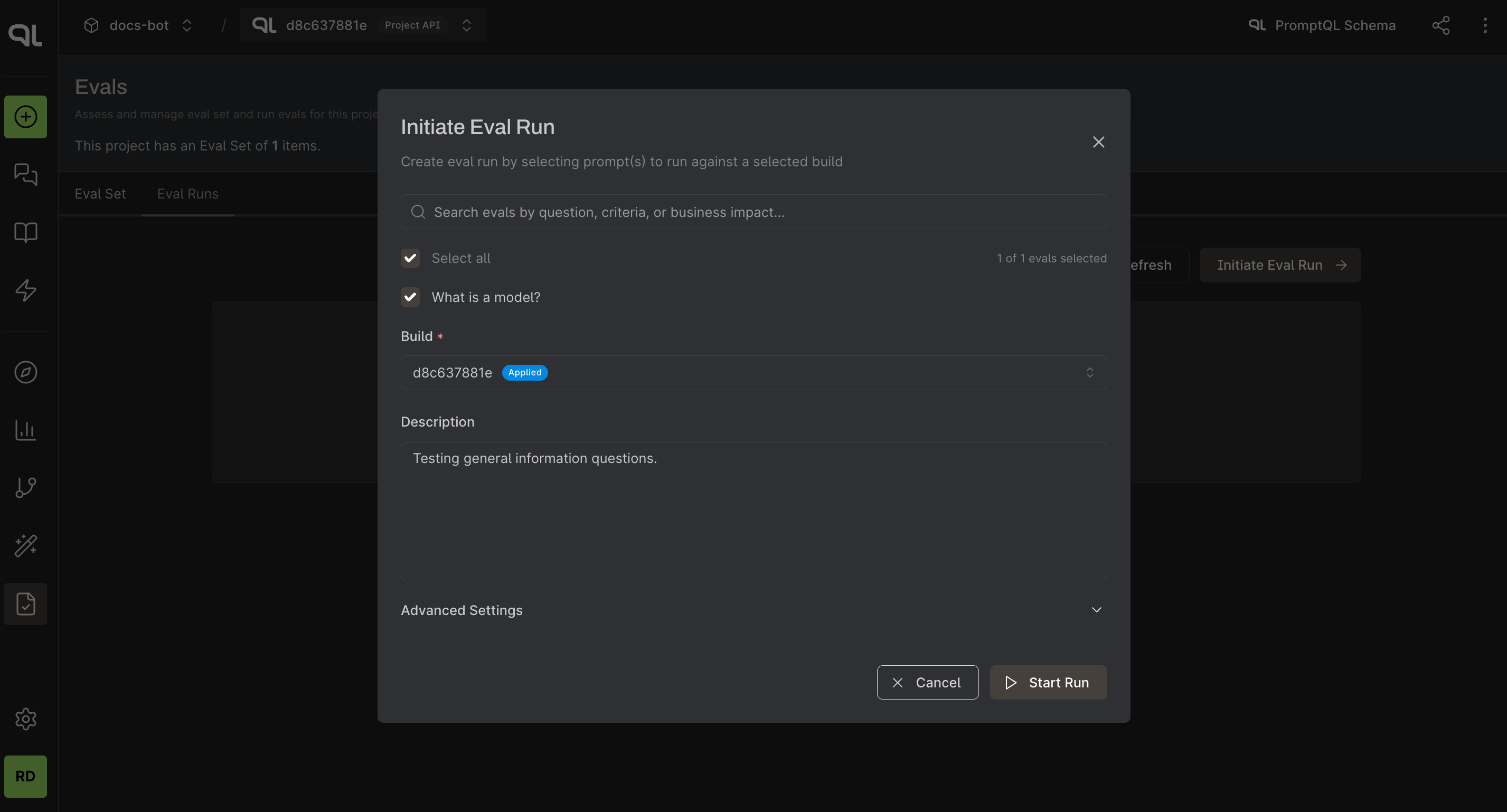
Step 2. Run the Eval
You should be able to see the list of eval items in the table once it's added. From here, you can run each eval item against your agent to see how it performs. You can give a description to the eval run and select a build to run the evals against (by default the build will be the one selected in console's global context in top navbar)
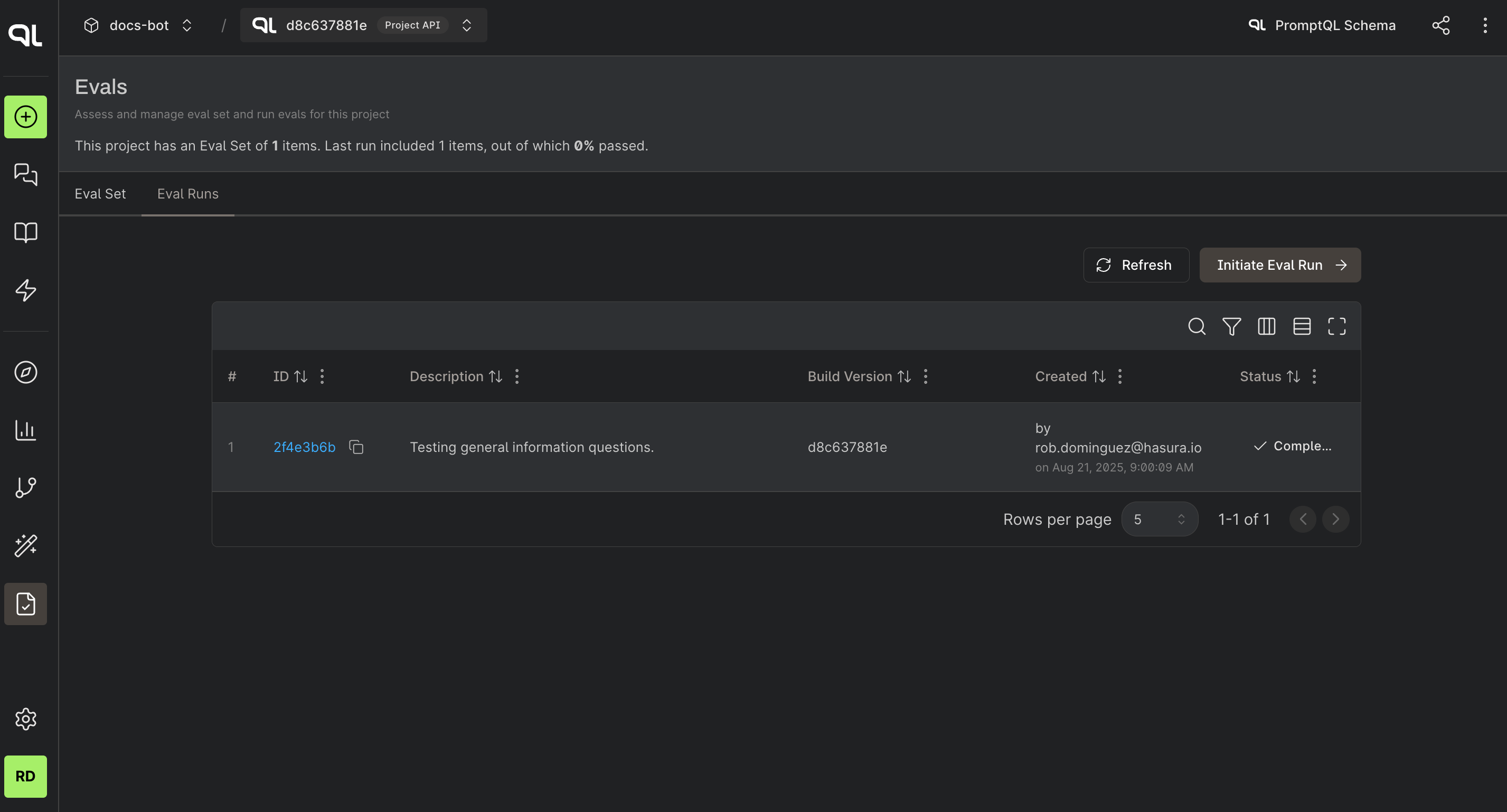
Step 3. Review the Results
Once the eval run is initiated, you can view the progress and results in the table. Once the eval runs are completed successfully, you'll see an eval ID which you can expand; this contains threads for each eval run. You can click on the thread to view the conversation and the results of the eval item prompt.
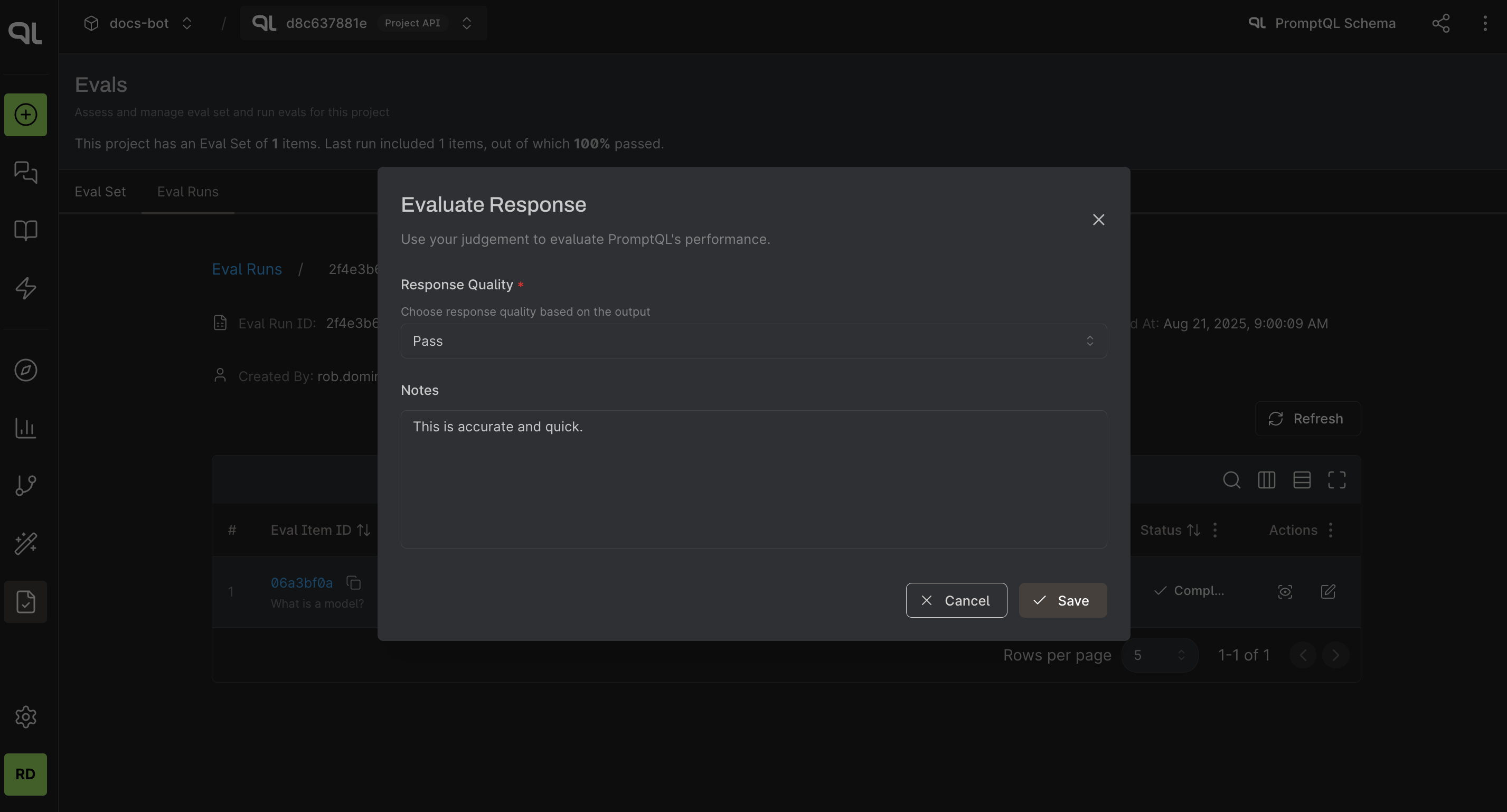
Step 4. Scoring the eval runs
After reviewing the results, you can score the eval runs based on how well the agent performed against the eval criteria
by clicking on the Edit Score button under the Actions column. You can also add comments to explain your score.
Next Steps
Ready to start evaluating your AI capabilities? Here are some recommended next steps:
-
Identify a use case - Choose a specific AI task you want to improve (e.g., customer support ticket classification, financial report analysis, or product recommendation accuracy)
-
Create test data - Develop a small set of representative examples that cover typical scenarios, edge cases, and potential failure modes
-
Set up your first eval - Start with simple, measurable criteria like "Does the response answer the question accurately?" or "Are the calculations correct?"
-
Run and iterate - Execute your eval against your current agent, review the results, and refine your criteria or test cases based on what you learn
Example: Customer Support Eval
Here's a practical example to get you started:
- Prompt: "A customer is asking for a refund on a product they bought 45 days ago. Our return policy is 30 days. How should we respond?"
- Tags:
category: customer-support,scenario: policy-exception,priority: medium - Eval Criteria: "Response provides accurate policy information, explains reasoning clearly, offers appropriate alternatives"
- Business Impact: "Ensures consistent, accurate responses to policy exception requests that maintain customer trust"
Evals are most effective when integrated into your regular development workflow, helping you build more reliable and effective AI-powered applications.