RESEARCH
Advancing Reasoning AI with Domain Specialization
Our Mission
Our research addresses the fundamental challenge of capturing & encoding domain-specific knowledge into reasoning AI systems. We investigate methods for capturing organizational semantics, procedural rules, contextual relationships etc. to create reasoning AI models that can perform analysis & automation tasks with enterprise-grade accuracy & reliability.
The Problem
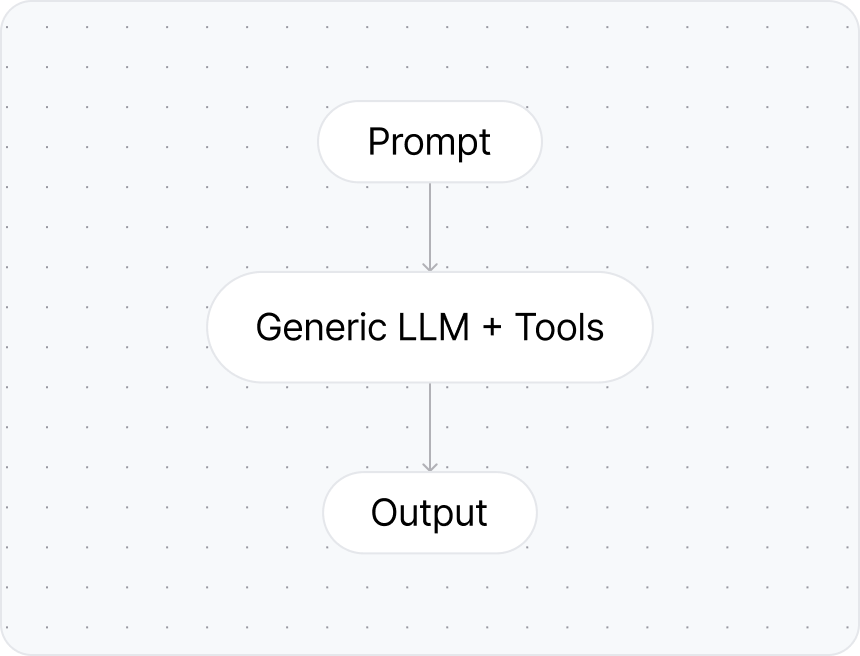
Generic LLMs lack domain-specific context and produce non-deterministic outputs for business-critical operations.
The Solution
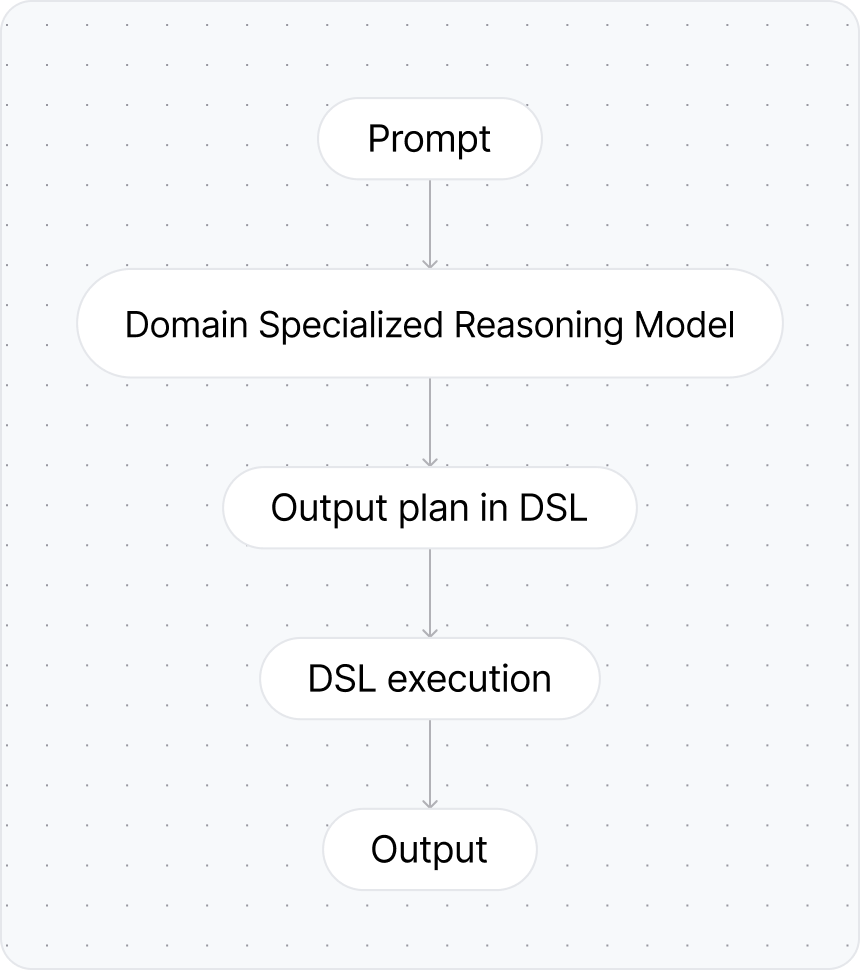
An architecture with domain-specialized components that separates planning from execution.
We define accuracy as:
Exact (or semantically exact) outputs when such accuracy exists
Explainable planning of how output was achieved when there are multiple "correct" outputs
Research Areas
Domain Learning Layer
Foundation models excel at general reasoning but struggle with the nuanced, often undocumented knowledge that powers real organizations—the specialized ontologies, evolved workflows, and hard-won expertise that exist nowhere in their training data. We’re developing a continuous learning system that captures and maintains this organizational intelligence by ingesting from three critical sources: live data systems (databases, APIs, analytics), knowledge repositories (documentation, code, dashboards), and ongoing user interactions. Through continuous knowledge capture and synthesis, we then enable foundation models to truly understand and evolve with your organization—whether through real-time context injection, fine-tuning, or advanced post-training techniques.
Domain-Specific Language
Our research explores a new computational paradigm: a DSL powerful enough for arbitrary computation, yet simple enough for non-technical users to understand, reliable enough for LLMs to generate, and precise enough to compile deterministically for secure sandbox execution. By solving these competing constraints, we enable AI to orchestrate complex data operations—federated retrieval, transformations, semantic reasoning—through domain-native execution plans that any insider can verify, like reading a colleague’s instructions rather than decoding programmer syntax.
Featured Updates
Join our mission
We're building the future of reliable enterprise AI. If you're passionate about solving the intersection of AI, enterprise systems, and human-computer interaction, we'd love to hear from you.