From: MIT - The GenAI Divide - State of AI in Business 2025From: Stanford - The 2025 AI Index Report
From our work with 50+ Fortune 500 and Silicon Valley firms, we believe that the complex and ever changing AI landscape makes it very hard for AI leaders to invest in the right AI approach or vendor for their use-case, and hold AI vendors or teams accountable to outcomes.
That’s why we created the GenAI Assessment Framework (GAF). It maps AI solutions across two durable dimensions:
Capability Mode – what the AI is expected to do
Customization Approach – how the AI is built and improved
Together, these axes form a 3×3 matrix. The matrix helps define your needs, classify solutions, and quickly spot where solutions fit, or where they don’t.
The GAF 3x3 will help you answer questions such as:
Are my ROI expectations reasonable?
Do I need a RAG solution or should I build a semantic layer?
Should I build with an open-source framework or buy a vendor solution?
What are the fundamental risks with my choice of AI tech stack?
How should I compare between two AI vendors that offer similar solutions?
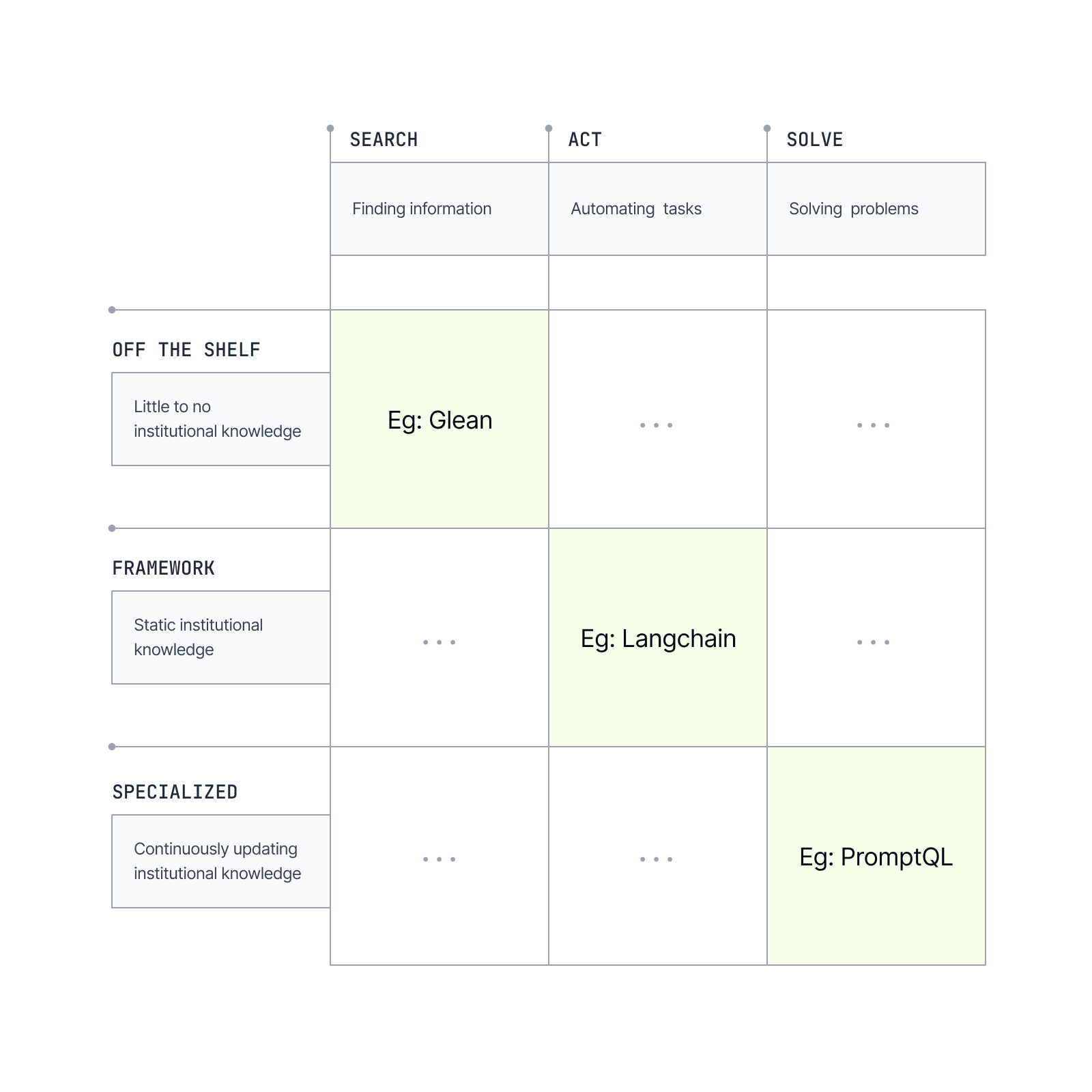
The GAF 3×3 Matrix
The GAF matrix maps AI solutions along two key axes: Capability Mode and Customization Approach. Think of it as a guide to ensure your chosen AI solution fits both your problem’s requirements and your organization’s strengths.
Axis 1: Capability Mode (What the AI does):
What the AI system does for the enterprise. This axis captures the primary purpose or function of the AI solution from the user’s perspective. These functions are aligned to the primary types of generative output that LLMs have been optimized for during pre-training. As LLMs get optimized to generate other fundamentally different types of output, these primary capability modes may grow.
Search (AI generates natural language): AI systems that perform read-only information access and synthesis. These systems retrieve and present knowledge from data, without directly modifying any external state. The canonical example is a question-answering system over enterprise documents (think RAG pipelines). The user asks, “What is our policy on X?”, and the system finds relevant text and summarizes an answer. Search-mode AIs are like intelligent librarians: great at finding and explaining information, but not expected to execute transactions or create new artefacts beyond reports/answers.
Act (AI generates tool/agent calls): AI systems that execute actions or workflows to change an external state on the user’s behalf. These go beyond providing information; they perform the next-best action in enterprise systems (with appropriate permissions). Examples include an AI that reads an email and then schedules a meeting, updates a CRM record, or triggers an IT helpdesk ticket. Often realized through agent frameworks or tool calls, Act-mode solutions essentially function as autonomous or semi-autonomous assistants that can carry out multi-step procedures (e.g. “Book me a flight and then file an expense report”). They must interface with enterprise applications (via APIs, RPA, etc.), and correctness/safety in execution is a key concern.
Solve (AI generates plans/code): AI systems that generate novel solutions or artifacts to open-ended problems. Here the output is not merely an answer to a query, but a concrete artifact that solves a problem: for example, writing a piece of software, producing a detailed plan or strategy, designing a workflow, or analyzing data to produce insights. Solve-mode AIs exhibit open-ended reasoning and often produce code or complex outputs that can be executed or implemented. A prime example is an AI that takes a natural language request (“Analyze our sales data and build an optimization model”) and generates a working Python script or SQL queries to do so. These solvers overlap with what some literature calls “autonomous agents,” but we use Solve to emphasize the creation of new solutions (often via code generation and iterative self-correction)
Axis 2: Customization Approach (How the AI is implemented & improved):
How the AI system is built, delivered, and improved. This axis captures the approach to customization & integration of institutional knowledge in the AI system, to get to the desired level of performance.
Off-the-shelf (Config-driven): Solutions that work out-of-the-box with standard configuration. These are typically vendor-provided SaaS or software with no-code setup, perhaps just connecting data sources and setting access controls. The key characteristic is that the user (often a non-engineer, like an IT admin or business user) can deploy the solution via configuration settings, and the solution does not fundamentally change its behavior over time except via vendor updates. It’s essentially static from the customer’s perspective – no custom code is written, and the model may not learn from your specific usage (beyond perhaps some caching or minor personalization). Time-to-value is fast, flexibility is limited. In our context, many enterprise “AI assistants” sold by vendors fall here: you toggle some settings, point it at your SharePoint or database, and it’s ready to use.
Framework (Code-driven): Solutions that require engineering to implement, typically using libraries, SDKs, or APIs. In this paradigm, developers assemble and orchestrate the AI system by writing code – for example, calling an LLM via API, connecting it to a vector database, implementing logic for tool usage, etc. The resulting solution can be tailored to the organization’s needs through code (which allows flexibility to handle edge cases), but the burden is on the development team to build and maintain that orchestration. The underlying models might still be pre-trained (not custom), and adaptation is achieved through explicit programming rather than the system learning by itself. This is essentially the “framework” approach, giving maximum control. Many open-source toolkits (LangChain, Transformers, Haystack) and cloud AI services (Azure OpenAI, AWS Bedrock, etc. which expose building blocks) support this mode. Flexibility is high, but learning is manual.
Specialized AI (Feedback-driven): Solutions that incorporate continuous learning and adaptation from user interactions or other feedback. Here, the system is not static; it improves over time by design. This could involve fine-tuning models on collected data, using reinforcement learning from human feedback (RLHF) or reward signals, employing retraining pipelines, or maintaining a growing knowledge graph/semantic layer that the AI consults. The defining trait is an intrinsic feedback loop: the solution has mechanisms to get better with usage (either automatically or through periodic retraining using captured feedback). Gartner refers to this class as Adaptive AI, meaning systems that “aim to continuously retrain models or apply other mechanisms to adapt and learn within runtime and development environments”. Implementations here range from vendor platforms that continuously incorporate user corrections (e.g. a self-improving chatbot whose answers get refined based on user up/down-votes), to custom in-house systems that retrain an LLM on transcripts of failures or maintain a dynamic memory outside the model. These solutions have the highest potential performance long-term, but are the most complex to build and govern, often requiring sophisticated AI & engineering maturity.
Each AI solution in the market can be plotted in this 3×3 matrix. For instance, a plug-and-play chatbot that answers customer FAQs would be Off-the-Shelf × Search. A platform like OpenAI’s API or an open-source LLM + toolkit combo used to build a custom agent would sit in Framework × Act. A from-scratch trained model for generating legal contract clauses would fall under Custom × Solve. The GAT matrix helps clarify these positions at a glance.
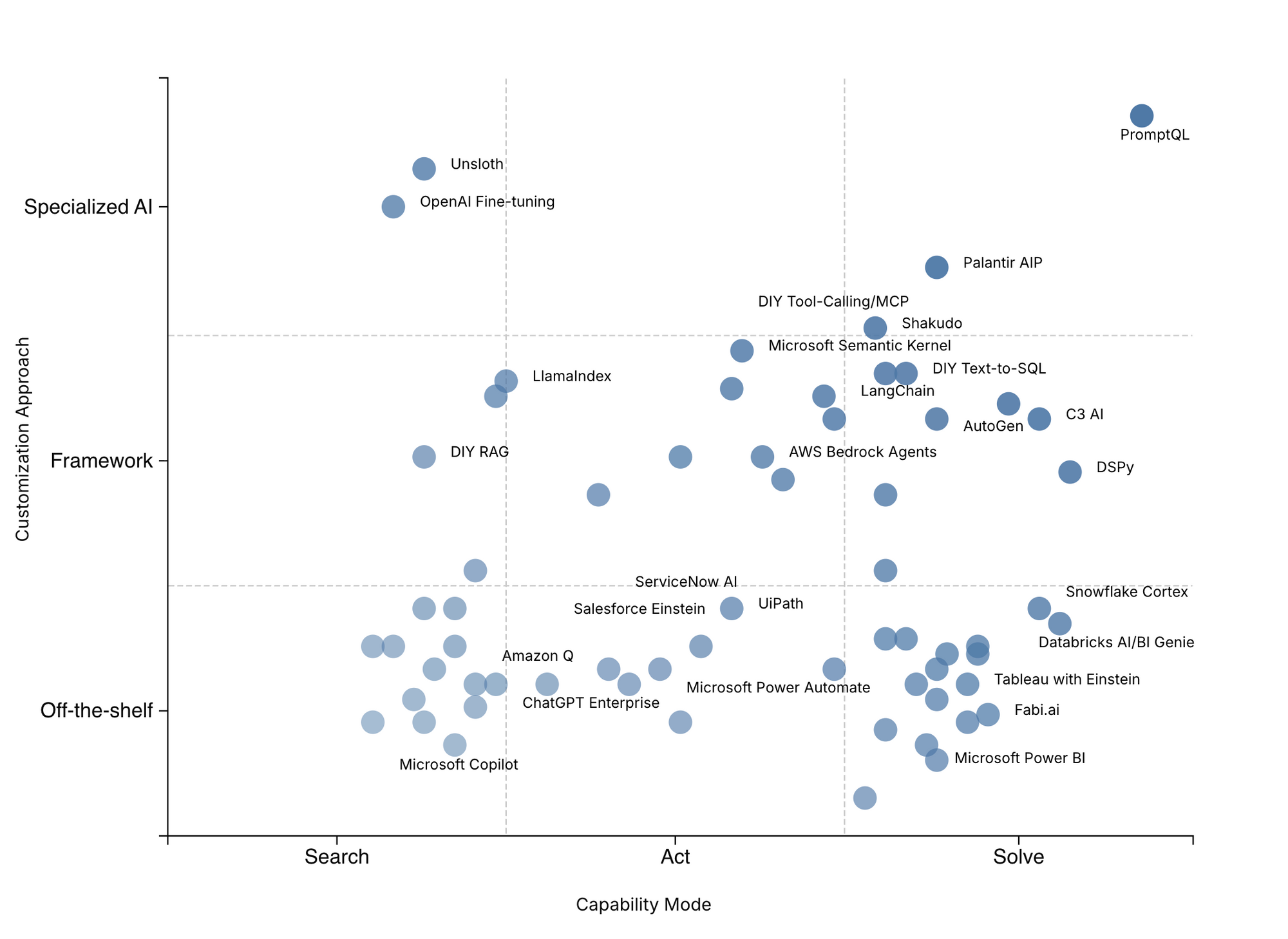
What We Analyzed: 50+ Solutions Across the Market
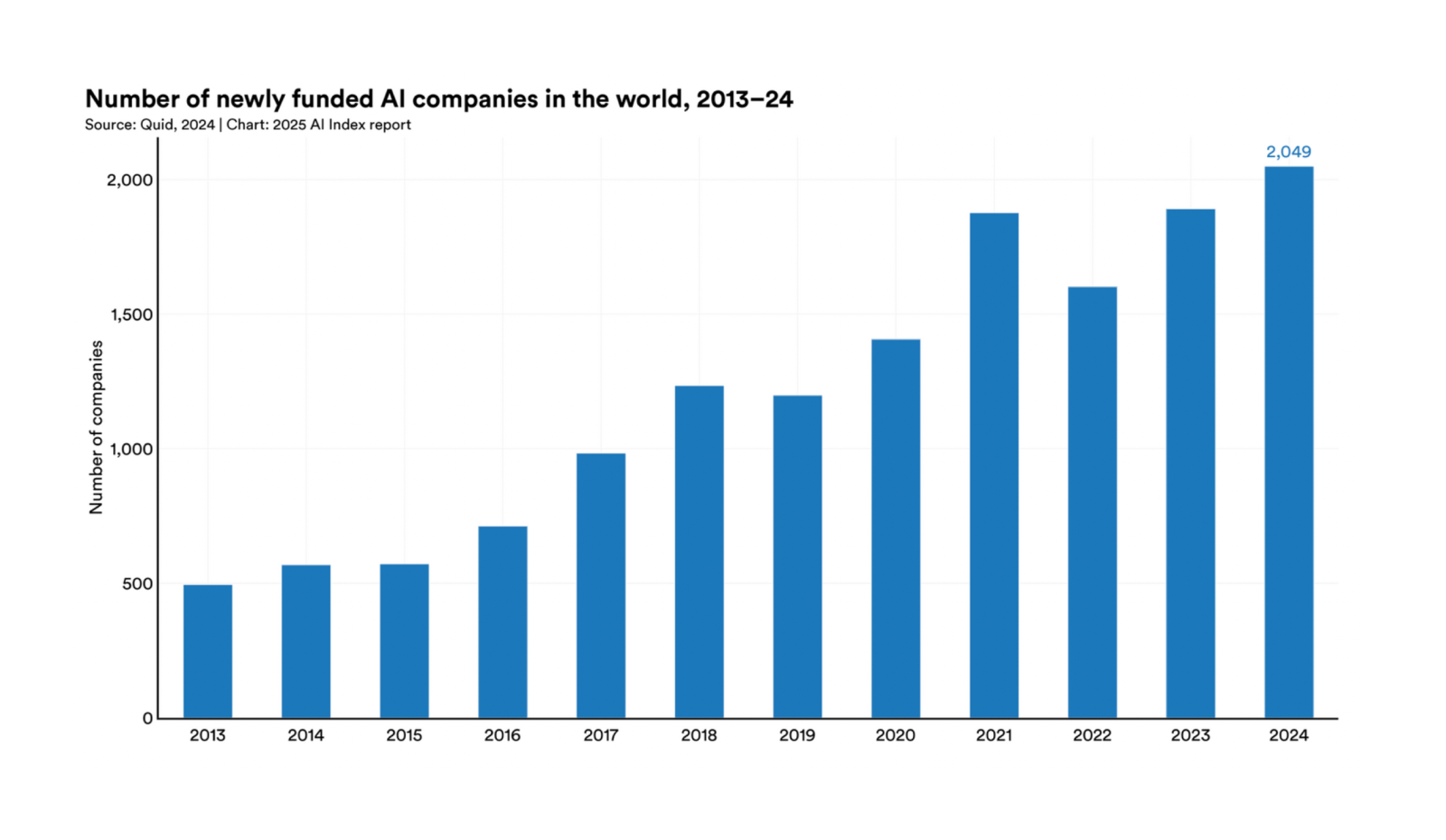
The generative AI tooling landscape is exploding, and it can be overwhelming. To bring order to the chaos, we analyzed 50+ prominent GenAI solutions – including hot venture-funded startups, established “legacy” vendors, and open-source (OSS) projects – and plotted them on the GAT 3×3 matrix. This exercise was illuminating: it shows how different players concentrate on different quadrants, and why alignment with your needs is everything.
Our analysis revealed clear patterns. Venture startups tend to cluster in the Off-the-Shelf cells (upper row), each tackling a narrow slice of Search or Act with a ready-made tool. Open-source offerings dominate the Framework row – providing building blocks for all three capability modes if you’re willing to assemble them. Legacy vendors often straddle the Off-the-Shelf and Framework approaches, leveraging their platforms to offer semi-customizable solutions (with a bias towards Search-mode applications, since those are broadly needed). No quadrant is “better” outright; the trick is to align your choice to your needs. If your problem lives in one cell (say, you need a Solve-mode coding assistant), buying a product from a different cell (say, a Search-oriented Q&A chatbot) is likely to disappoint. The 3x3 matrix helps you quickly sanity-check this alignment.
Why Enterprise AI Projects Fail: The Framework Reveals All
Failure Mode 1: The "Learning Gap" in Enterprise Tools
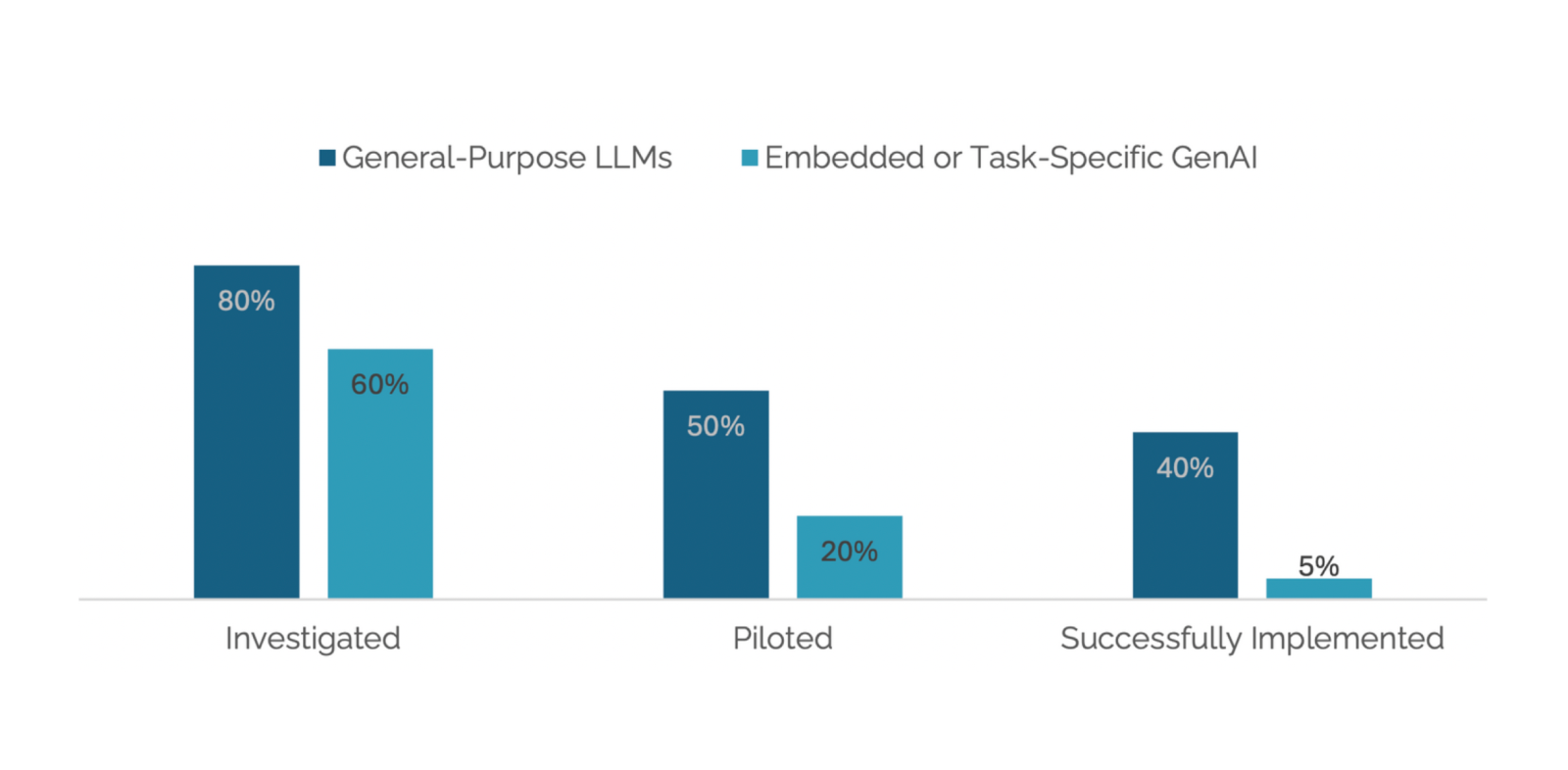
A primary failure identified in the MIT report is the "learning gap," where enterprise AI tools are static and do not improve with user feedback. A survey found the most common user complaint (from 60% of users) was that the AI "doesn't learn from our feedback". This leads to users abandoning the tools because they repeatedly make the same mistakes and fail to retain context from previous interactions.
Organizations deployed static systems that provide information or perform fixed tasks. This falls into the Off-the-shelf or Framework archetypes, which are not designed to adapt on their own. The business need was for a system that could learn user preferences, retain context, and improve over time. This requires an investment in the feedback-driven Specialized paradigm, that can adapt its creative or analytical output based on user corrections.
Failure Mode 2: The Misaligned Assistant
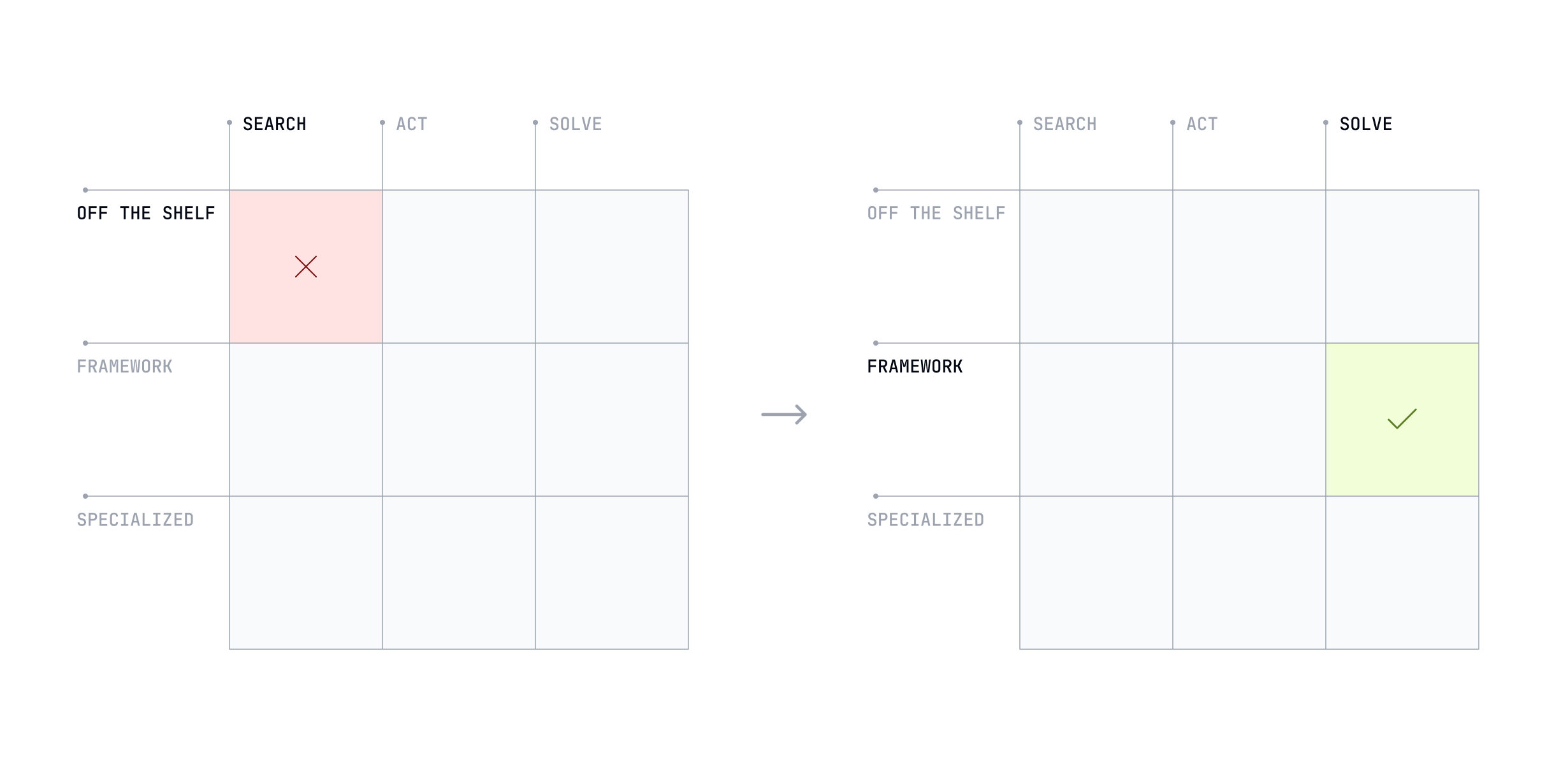
The MIT report provides a specific anecdote of a corporate lawyer whose firm spent $50,000 on a specialized AI tool for contract analysis. She ultimately rejected it in favor of a general-purpose tool like ChatGPT because the expensive enterprise tool only provided "rigid summaries with limited customization". Her actual workflow required an interactive, iterative conversation to draft and refine legal documents, a capability the tool lacked.
The firm purchased a tool that performed a simple, one-shot summarization task. This is a classic Search / Off-the-shelf solution. The lawyer's workflow involved creative drafting and iterative refinement, which is characteristic of the Solve capability mode. She needed a Solve / Framework tool that could act as a collaborative partner in creating a new artifact (the legal draft), not just summarizing an existing one.
Failure Mode 3: Piecemeal Pilots Lacking Transformative Impact
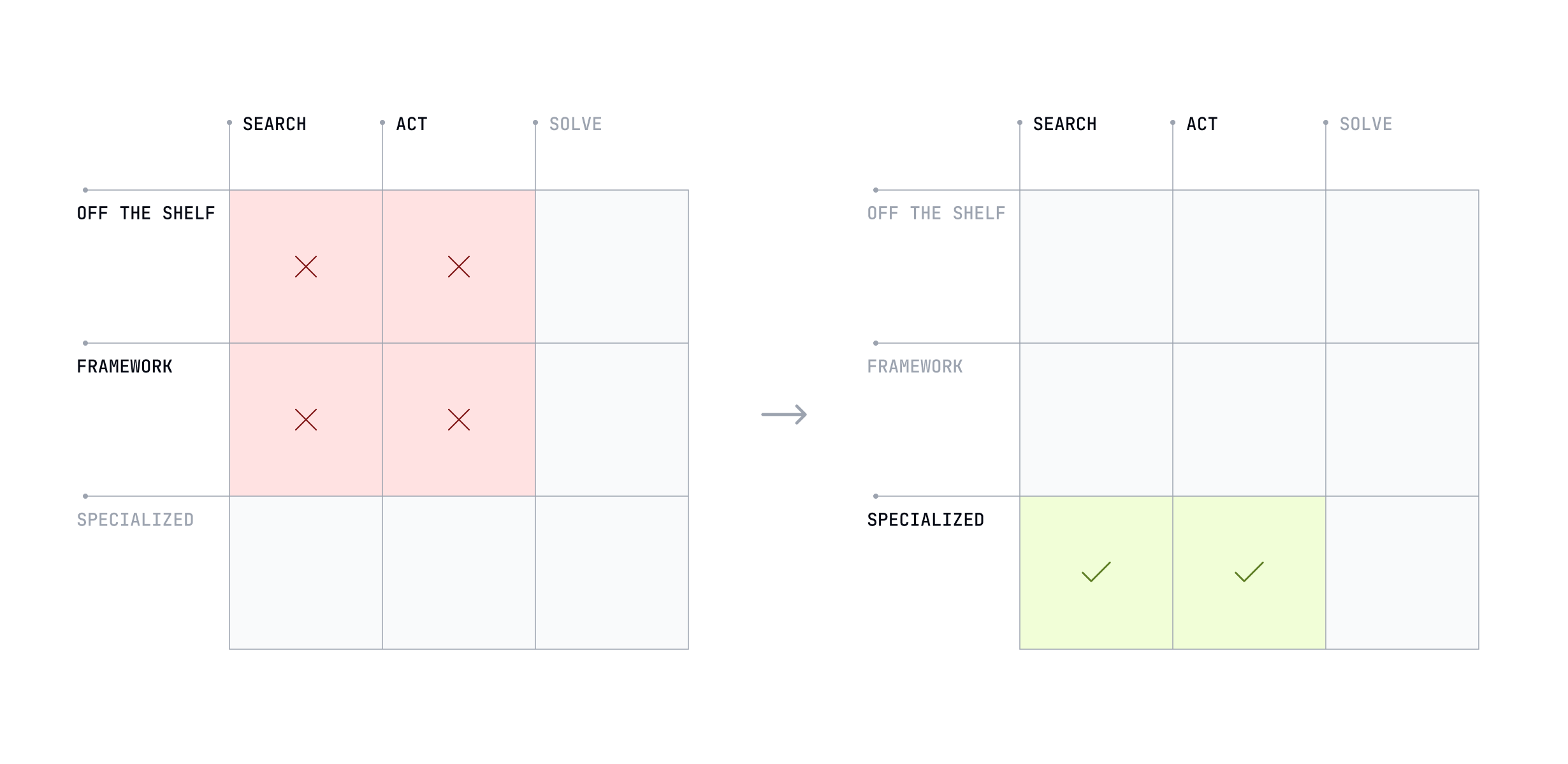
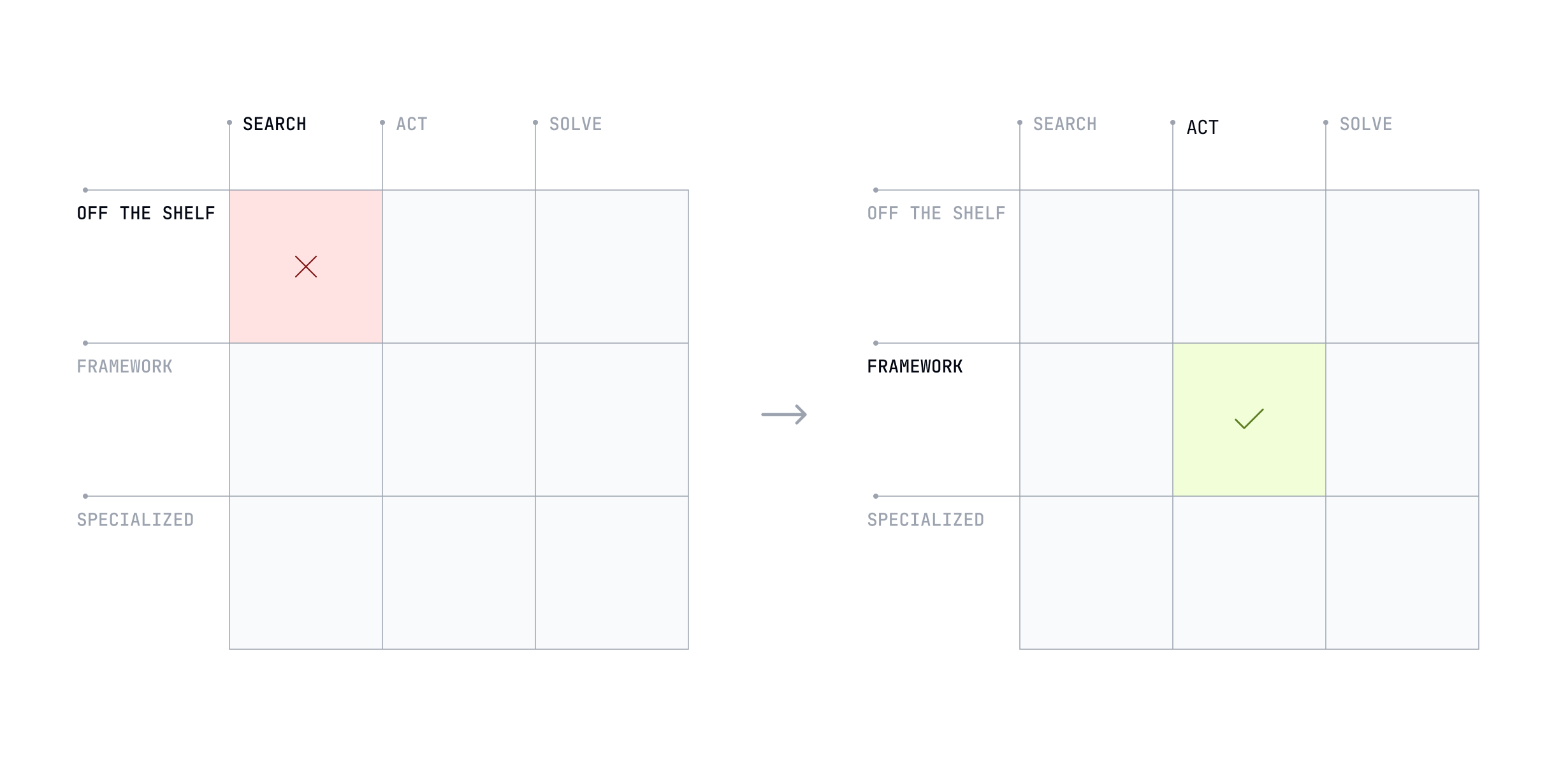
McKinsey researchers observed that many companies take a "piecemeal, use-case-by-use-case approach" to AI, resulting in many isolated pilots but no "wholesale transformative change". These pilots are often simple Q&A bots or summarizers that don't integrate into or automate core business processes. This leads to the widely reported 95% statistic, because they never address end-to-end workflows.
Companies deployed numerous, disconnected pilots that were overwhelmingly simple information retrieval bots. This represents an over-investment in scattered Search / Off-the-shelf solutions. To achieve transformation, organizations needed to automate and redesign entire business processes. This requires AI that can execute multi-step workflows and interact with other enterprise systems, which is the definition of the Act capability mode, likely requiring custom integration (Act / Framework) to be effective.
Failure Mode 4: High Failure Rate of Internal "Build" Projects
The MIT report highlights that AI solutions built entirely in-house have a much lower success rate (~33%) compared to those developed with specialized external partners (~67%). This is companies overestimating their own capabilities and attempting to build complex, adaptive systems without the necessary talent, MLOps maturity, or resources.
Organizations with little to no in-house AI expertise attempted to create highly customized or learning-based systems on their own. This was a failed attempt to operate in the Framework or Specialized AI paradigms. Given their internal constraints (e.g., lack of ML engineers), a more appropriate and successful strategy would have been to either purchase a vendor solution or partner with experts.
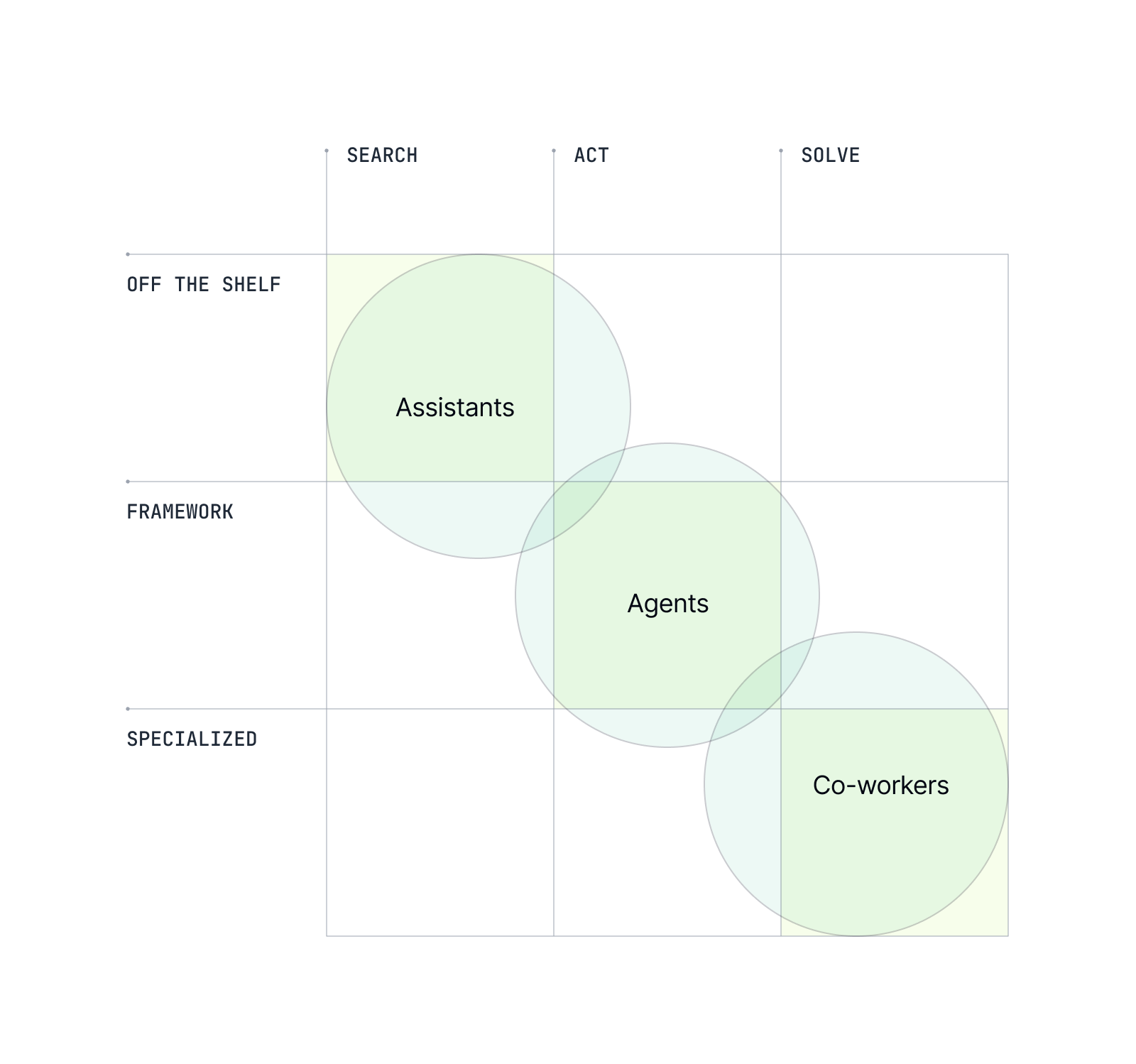
The Logical Evolution: Assistants → Agents → Co-workers?
We’ve watched enterprise AI march from “Assistants” (Search/Off-the-shelf) that mainly retrieved and summarized info, toward “Agents” (Act/Frameworks) wired into workflows—driven by companies redesigning processes and embedding AI with mechanisms to capture feedback and improve over time. In 2025 the center of gravity is shifting again to true “Co-workers”: adaptive solvers that learn on the job, retain context, and collaborate to produce code, analyses, and decisions; an evolution buyers are explicitly demanding and vendors are enabling. A key emerging AI behavior is the ability of the "co-worker" to be multiplayer, i.e. identify its gaps in knowledge and seek information from unstructured sources, colleagues, etc. to fill those gaps. Early labor-market clues from Stanford’s Canaries in the Coal Mine reinforce why this next step matters: AI is already displacing routine entry-level work while complementing experienced workers, pointing to a world where adaptive AI “co-workers” shoulder more of the solving while humans steer outcomes.
Take Action: Get Your Custom GenAI Assessment Test
Achieving success in enterprise AI doesn’t have to be a moonshot. With the right rubric and strategy, you can systematically join the 5% that get real value. This is exactly why we’re launching the GAT Design Service – a vendor-agnostic diagnostic engagement to map your workloads and vendor landscape onto the 3x3 matrix, and chart the optimal path forward. In just 5 working days, an AI engineer (with experience shipping AI to production) will work with your team to deliver:
A Custom GAT for Your Use Case: A set of evals and a scoring rubric tailored to your business problem – covering accuracy metrics and non-functional requirements (latency, cost, etc.). This “AI SAT” defines what success looks like in measurable terms.
3x3 Recommendation Report: A clear recommendation of which AI Capability Mode x Customization Approach combination will meet your goals most economically. Whether it’s Off-the-Shelf, Framework, or Specialized – and whether the solution should focus on Search, Act, or Solve – we’ll identify the sweet spot to get the highest GAT score for the least cost/risk. We’ll also outline the risks, trade-offs, and vendor options for that approach.
Actionable Roadmap: A report that makes vendor claims and in-house options testable side-by-side. It aligns stakeholders on a common evaluation framework and shortens the path from proof-of-concept to production. In essence, you get an AI battle plan grounded in data and tailored to your domain.
Evals, institutional knowledge, and workload mapping are the three pillars of our methodology. We ensure your AI strategy is grounded in reality: Evals protect you from hype by enforcing evidence-based decisions, institutional knowledge drives how much customization you need, and mapping to LLM output types ensures you leverage what these models actually do well. With your GAT in hand, you’ll have the clarity to avoid false starts and focus on solutions that work for you.
Ready to turn your AI pilots into scalable successes? Don’t be part of the 95% that stumble – be the 5% that soar.Reach out to us to book your GAT Design Service and let us help you ace the “GenAI Assessment Test” for your initiatives. Together, we’ll map your AI to the right 3x3 strategy and set you up to finally get ROI from AI. Your custom “AI SAT” awaits – let’s ensure your enterprise passes with flying colors.