The reason humans are so useful is not mainly their raw intelligence. It’s their ability to build up context, interrogate their own failures, and pick up small improvements and efficiencies as they practice a task- "Why I don't think AGI is right around the corner", Dwarkesh Patel
In this post, based on our recent experiences selling 7-figure AI deals to Fortune 500s and Silicon Valley tech cos alike, I'll discuss how "confident inaccuracy" seems to be at the heart of this problem.
Aside from the hilarious "Oh I spend $10M on this campaign because our AI assistant told me to" first order problem, confident inaccuracy causes second and third order problems that are far more insidious:
a) Imposes a universal verification tax
I don't know when I might get an incorrect response from my AI. So I have to forensically check every response.
My minutes turn into hours; the ROI disappears.
b) Erodes trust asymmetrically
For serious work, one high‑confidence miss costs more credibility than ten successes earn.
I'll revert to my older flow.
c) Hidden failure modes kill motivation to improve
Without high-quality uncertainty information, I don’t know whether a result is wrong because of ambiguity, missing context, stale data, or a model mistake.
If I don't know why its wrong, I'm not invested in making it successful.
d) Compounding errors results in AI being doomed to fail
There's been a slew of recent reports on AI adoption is not trending well.
Per McKinsey's report 90% of AI initiatives stay stuck in pilot mode. Fortune covered an MIT study that claims 95% of pilots are failing.
While the authors of the reports point out several issues, consider another perspective - at the core there are 2 simple facts:
A system is either always accurate or its not
If the system is not always accurate even the tiniest percent of the time, I need to know when its not.
No amount of solving any other problem (integration, data readiness, organizational readiness etc) will change the fact that AI's tendency to be confidently wrong keeps it out of real world use-cases.
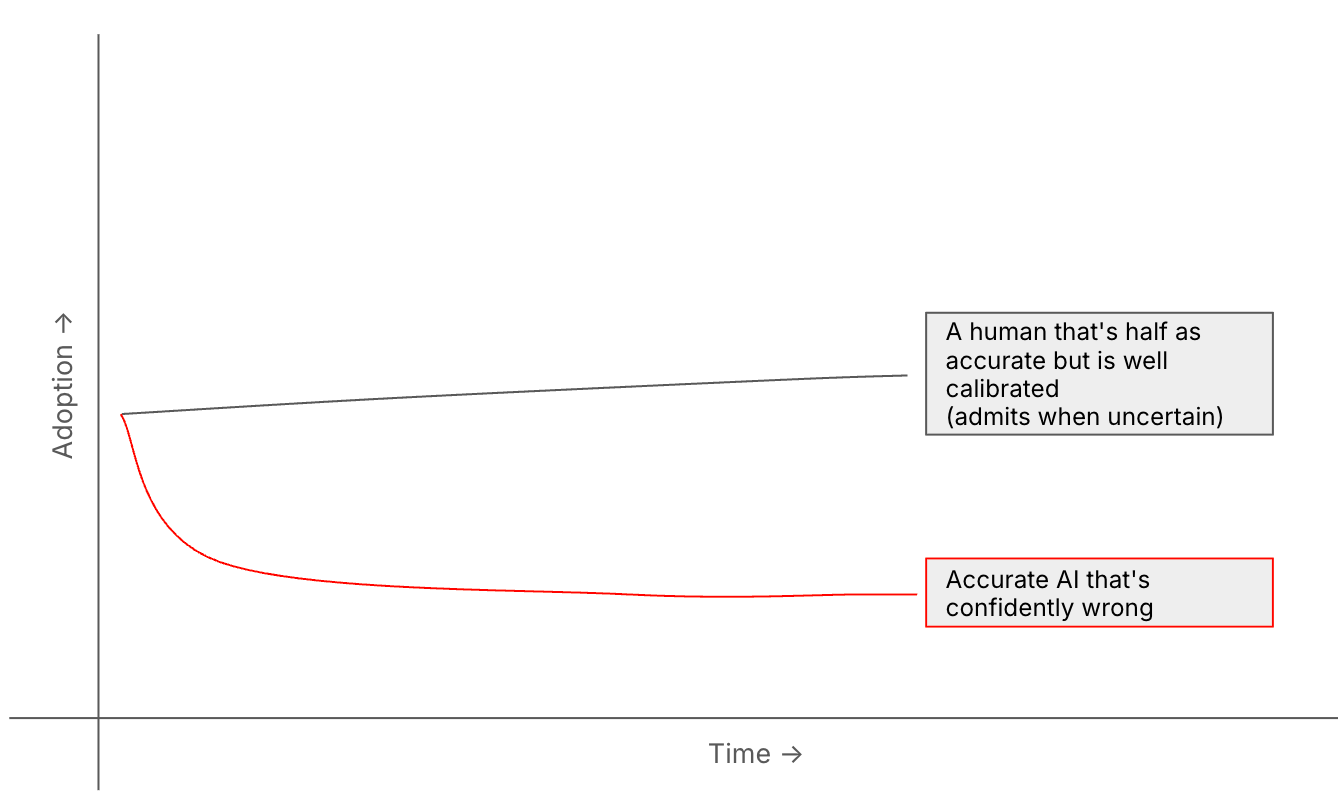
Accuracy is not like Uptime.
99.99% uptime is ~53 minutes a year.
99.99% accuracy in a ten step workflow is 1 error in a 1000 runs.
90% accuracy in a ten step workflow is 2 in every 3 workflows have errors (1 - 0.9^10).
2. Fixing "confidently wrong" might be A Silver Bullet™
The irony here is that perfect accuracy is not required to have a usable AI system.
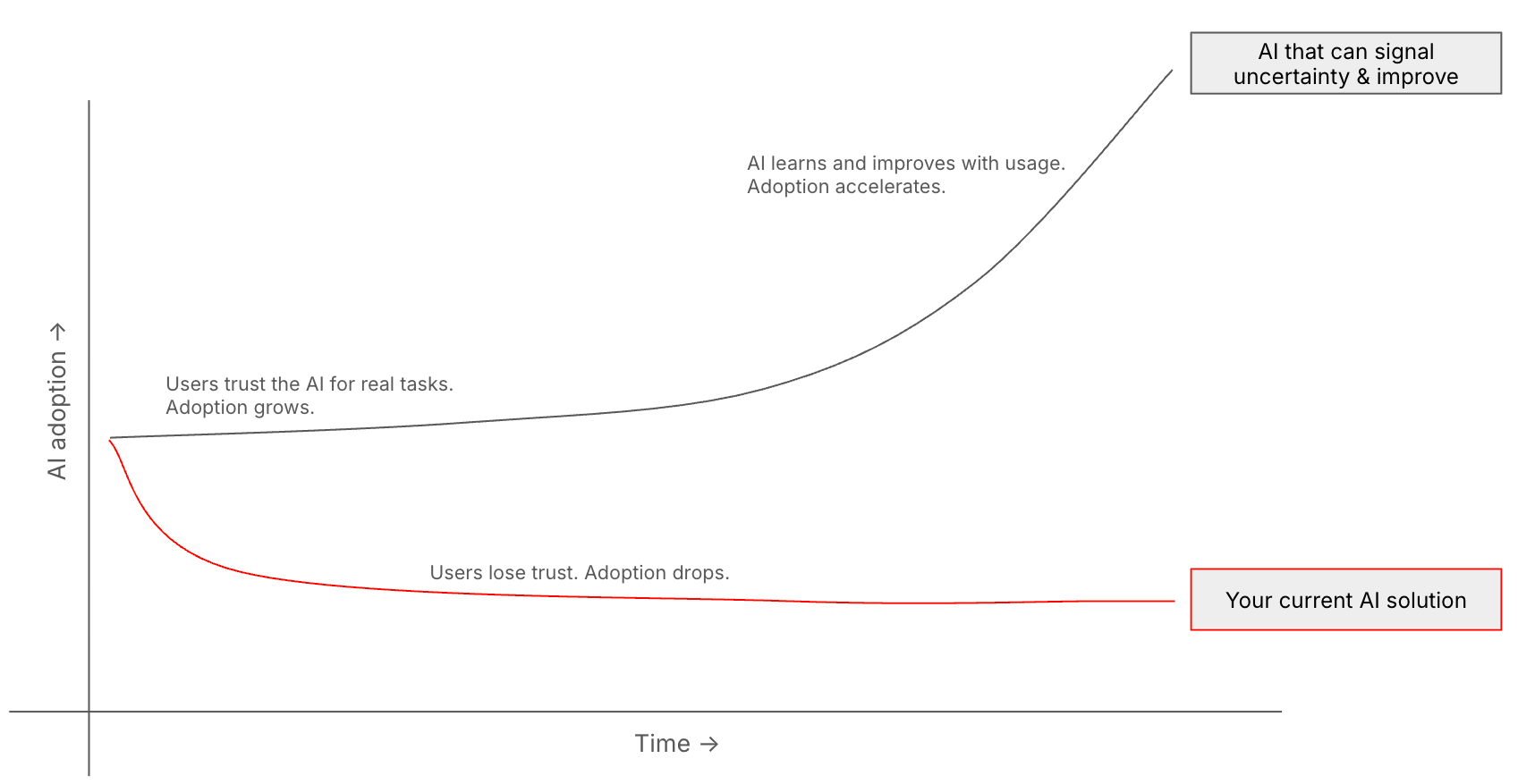
As humans if we're working with systems that will never be fully accurate, then more valuable than, say, a 90% accurate system is, say, a 50% accurate system that can signal uncertainty - and get more accurate over time.
We don’t need perfection; we need a loop that tightens.
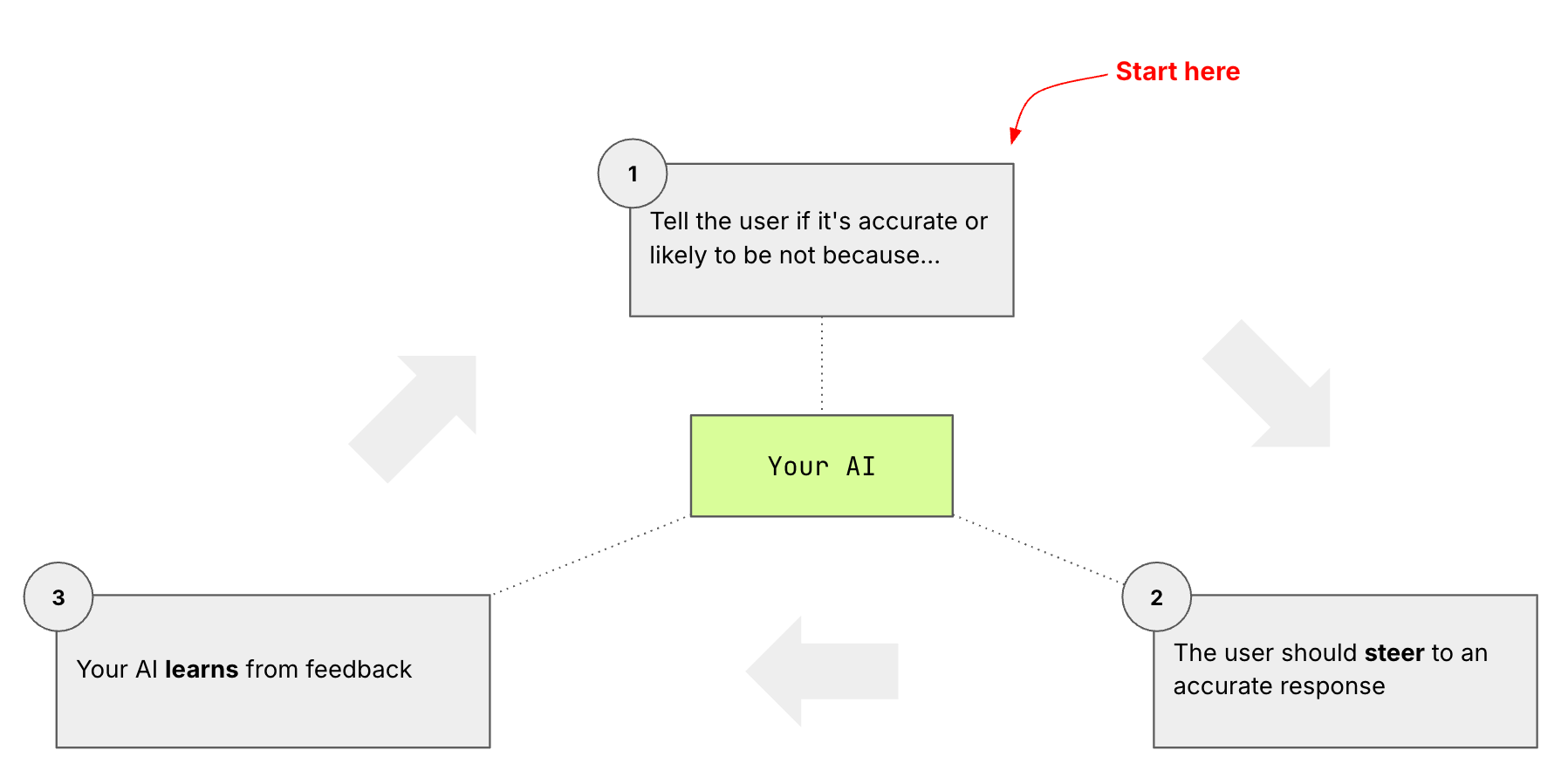
2.1 An Accuracy Flywheel
The starting point of this loop is if an AI system could tell the user when its not certain about its accuracy in a concrete and native way.
Native uncertainty → it signals confidence and the top uncertainty causes; abstains below threshold.
Human nudge → the user fills a planning gap that was causing uncertainty
Model improvement → that nudge updates the domain knowledge and the planning space (not just the answer) and accuracy improves.
In practice, the sources of inaccuracy are far more challenging, not just missing definitions of terms that need to be remembered.
Data is messy. The quality is unknown. Data is stale - especially unstructured data that lacks annotations. Procedural semantics are in people's heads. The list is endless.
A path to increasing AI Adoption vs Obsolescence
If our AI systems can tell us that they're not sure and why, then we can start to help it become better.
A quick diagnostic for your AI investment
Before you fund another “AI for X” pilot, ask:
Will it tell me when it’s unsure—and why? Ambiguity, missing context, data staleness, validation failure etc etc?
Does it learn from the correction I just gave it? Will the next user avoid the same trap without re‑prompting?
Our solution approach
Two principles have proven to work really well for us across customers:
Instead of generating answers, generate plans in a DSL unique to your domain. Plans in the DSL compile to deterministic actions with runtime validations and policy checks and the DSL should be rich enough to capture the breadth of data/API operations, compute tasks and of course generative & semantic AI tasks.
Continuously specialize the AI to your domain to drive planning accuracy & planning confidence. Build a system to continuously bind the AI model to your ontology/metrics, entity catalogs, data systems; learn your naming collisions and edge‑cases; understand your meanings and how your domain works. Most crucially, build a system that can leverage this to carry a calibrated confidence on the generated plan.
The mechanics are open to debate and require solving hard design & engineering problems - but solving for this takes us closer to a usable enterprise AI system.
If you lead data / AI initiatives and want to exchange notes feel free to reach out at [email protected].