Solve these 6 hidden architecture problems to turn your data warehouse into an AI powerhouse
Your data team has built impressive Snowflake infrastructure. Clean pipelines, well-governed tables, strong security controls. The business is excited about AI possibilities.
Yet your AI agent may still misclassify your biggest enterprise client as a high-risk customer. Why does this happen?
Why doesn’t the agent understand what you mean by “high-value prospects"? And how do simple questions return different answers each time they're asked?
The problem isn't your data quality or your models. It's a fundamental architecture gap that's quietly undermining enterprise AI initiatives across major data infrastructure deployments. Most data teams don't recognize these challenges until their AI projects fail in production.
This article explores the six architecture problems blocking reliable AI on enterprise data infrastructure:
Semantic gaps
Context stuffing into LLMs
Static knowledge systems
Fragmented data sources
Speed vs accuracy tradeoffs
Data security in federated access
We conclude with how forward-thinking organizations are solving them to build AI agents that actually work at scale with PromptQL.
Semantic gaps → loss of context
Large language models (LLMs) excel at pattern matching but struggle with business context. When your sales agent asks for "high-value prospects," the LLM doesn't understand that in your organization this means enterprise accounts with >$100K ARR potential, active engagement in the last 30 days, and no current contract conflicts. Instead, it might surface every account with high transaction volume – including those flagged as litigation risks.
Traditional knowledge graphs and semantic layers promised to solve this, but they've become maintenance burdens. Every business rule change, new data source, or metric redefinition requires manual updates across multiple systems. Data teams spend more time maintaining knowledge layers than delivering value.
Modern AI needs semantic understanding systems that evolve automatically with business operations – not static definitions that become technical debt.
Context mishandling → hallucinations and unpredictability
Most AI-powered analytics tools rely on glorified prompt engineering. They inject table schemas, data and business definitions into prompts, hoping LLMs can figure out the rest. Teams either overwhelm the context window with thousands of definitions (making responses slower and more expensive), or provide insufficient context (creating inaccurate, hallucination-prone results).
This approach creates three critical failures:
Context overruns: LLMs have large but finite context windows. Schema definitions for 200 tables plus business rules plus security constraints quickly hit limits. The LLM drops important context to accommodate new information.
Fluctuating outcomes: Identical questions return different results because LLMs weigh context differently each time. Your active customer count might swing between 10,000 and 12,000 customers depending on which context made it into the prompt.
Hallucination amplification: Partial context causes LLMs to fill gaps with plausible but incorrect information. They'll confidently reference database columns that don't exist or business rules never implemented.
Static knowledge systems → outdated business context
Modern businesses evolve constantly. New products launch, pricing models shift, organizational structures change, customer definitions expand. Each change breaks something in traditional semantic layers.
Data teams become bottlenecks, manually updating definitions and rebuilding connections. Knowledge systems meant to democratize data access become bureaucracies that slow everything down.
Effective AI requires semantic understanding that learns from actual business operations – not just static definitions from months ago. These systems should automatically understand that "enterprise customers" now includes your new SMB tier, or that "active users" must account for your recently launched mobile app.
Fragmented data sources → ETL nightmares
Enterprise presentations show elegant diagrams where critical data lives in unified warehouses. Reality is different. Customer lifetime value calculations need Snowflake transaction data, Salesforce opportunity data, ServiceNow support tickets, and product usage metrics from multiple operational systems.
AI agents don't automatically connect these dots. Traditional ETL approaches create maintenance nightmares that grow exponentially with each new data source. Meanwhile, business stakeholders can't wait months for data engineering teams to build pipelines – they need answers now.
Effective solutions build AI systems that work across actual data landscapes – Snowflake plus everything else – without requiring expensive duplication and transformation processes.
Federated data access → exposure and security risks
Current security approaches excel at protecting access when individual users access single systems. This becomes problematic in agentic scenarios where one AI system accesses many underlying data sources. Ensuring all access policies across multiple systems are honored – especially at AI operating speeds – creates significant challenges.
Traditional AI tools often treat existing access controls as suggestions rather than requirements. They bypass Snowflake's native security to create their own connection patterns. A marketing analyst's innocent campaign performance question might expose PII from customer support tickets they should never access.
Most AI systems don't maintain audit trails mapping back to existing governance frameworks. When regulators ask "who accessed sensitive data and why," teams face LLM query logs impossible to correlate with actual business users and their permissions.
Proper architecture preserves existing security models while extending them to AI interactions. Governance rules shouldn't become technical debt when adding intelligence to data systems.
Speed and accuracy tradeoffs → low user trust
Users want instant insights they can trust and rely upon. Most AI tools force choosing between speed and accuracy.
Fast systems provide answers in seconds by assuming data models and business rules. When assumptions prove wrong – which happens frequently – teams get confident-sounding results that lead to poor business decisions.
Accurate systems validate every assumption, check constraints, and verify calculations. By the time answers arrive, business opportunities have passed.
The breakthrough comes from treating this as an architecture problem rather than a trade-off. Systems that truly understand business context deliver both speed and accuracy because they're not constantly relearning what data means.
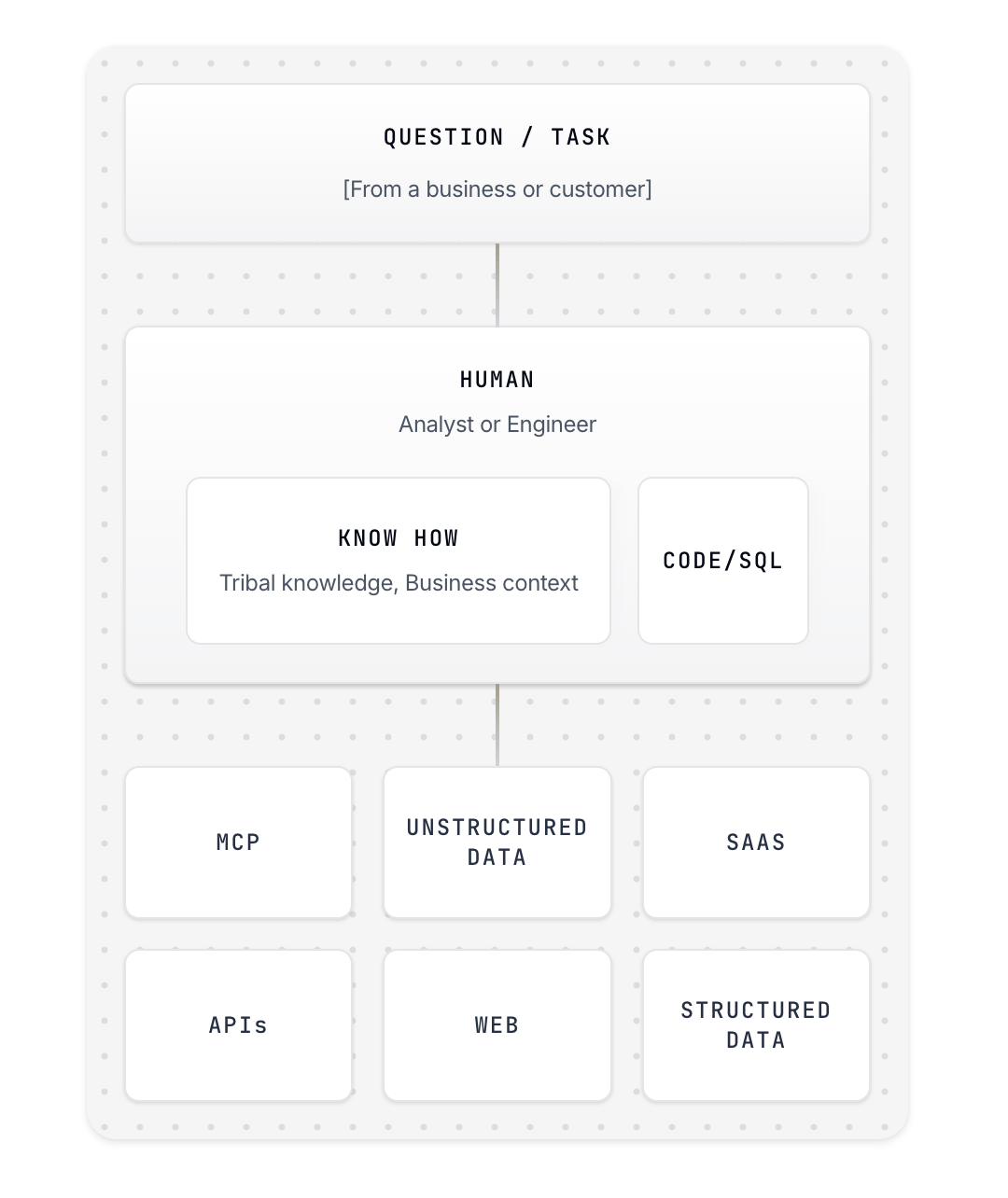
How PromptQL solves these architecture problems
Fig 2: How PromptQL is architected to bring human-level reliability to your AI agents
PromptQL takes a fundamentally different architectural approach. Instead of cramming business context into LLM prompts, we build an "agentic semantic layer" – a living understanding of your data landscape that evolves automatically with your business.
Self-Learning Business Context: PromptQL captures how teams actually define "active customers" or "adjusted revenue" in practice. When business rules change, the system adapts automatically instead of requiring manual metadata updates.
Deterministic Execution: PromptQL uses LLMs to generate multi-step query plans in our domain-specific language, then executes those plans deterministically outside LLM context. This delivers LLM intelligence for planning with traditional code reliability for execution. No context overruns, fluctuating outcomes, or hallucinations about nonexistent data.
Federated Intelligence: Instead of forcing ETL into Snowflake, PromptQL's federated query engine connects directly to data wherever it lives – Snowflake, Salesforce, operational systems, APIs, web sources. The agentic semantic layer infers and maintains deterministics relationships, ontologies and business logic while the query engine handles technical complexity.
Security-Preserving Architecture: PromptQL preserves and extends existing Snowflake security models. Row-level security, column masking, and access controls work exactly as today, but now apply to AI interactions. Access control rules are enforced by a deterministic data access layer, and not left to LLM guardrails. Every query maintains complete audit trails mapping back to business users and their permissions.
The result is AI that works like your best analyst – understanding your business deeply, working across all systems, explaining reasoning clearly. Unlike human analysts, this system scales infinitely and never forgets what it learned about your business.
And when your AI can reliably answer your business’ core questions, your organization becomes curious and innovates more.
Building AI that actually works
Companies solving these architecture problems first gain insurmountable advantages. They make better decisions faster, spot opportunities while competitors argue about data definitions, and trust AI insights enough to act immediately.
Companies that don't will keep building impressive Snowflake deployments that can't power the AI applications their businesses actually need.
PromptQL has solved these architecture problems for Fortune 100 companies across healthcare, finance, and technology. Our customers build AI agents performing at staff-level reliability because we've taught AI systems to understand business context at the same depth as experienced analysts.
Ready to see enterprise-grade AI agents in action?Schedule a demo and discover how Fortune 100 data teams are building AI agents that work with their data reality, not against it.