TL:DR: We've spent the last year realizing that AI will soon do everything provided enough useful context. The alpha has shifted from using AI to maintaining useful context.
The AI hype cycle we're in hinges on the hypothesis that one person with good enough AI can do what would take a team. It does seem like this is quite achievable for software engineering and research tasks where the verification of work is cheaper than the doing of the work, in line with Jason Wei's Asymmetry of Verification.
However, for most non-coding tasks, even coding adjacent work like product, analytics, it doesn't seem like the one-man–with-agent-army operating model has made nearly the same amount of progress.
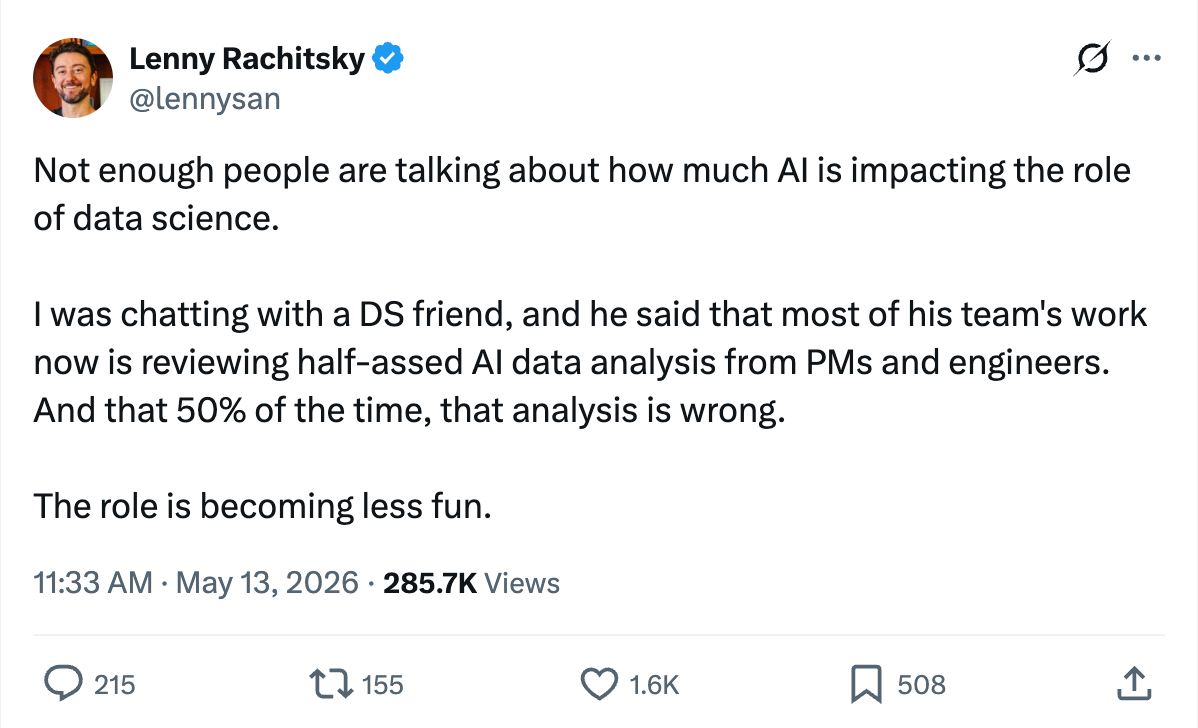
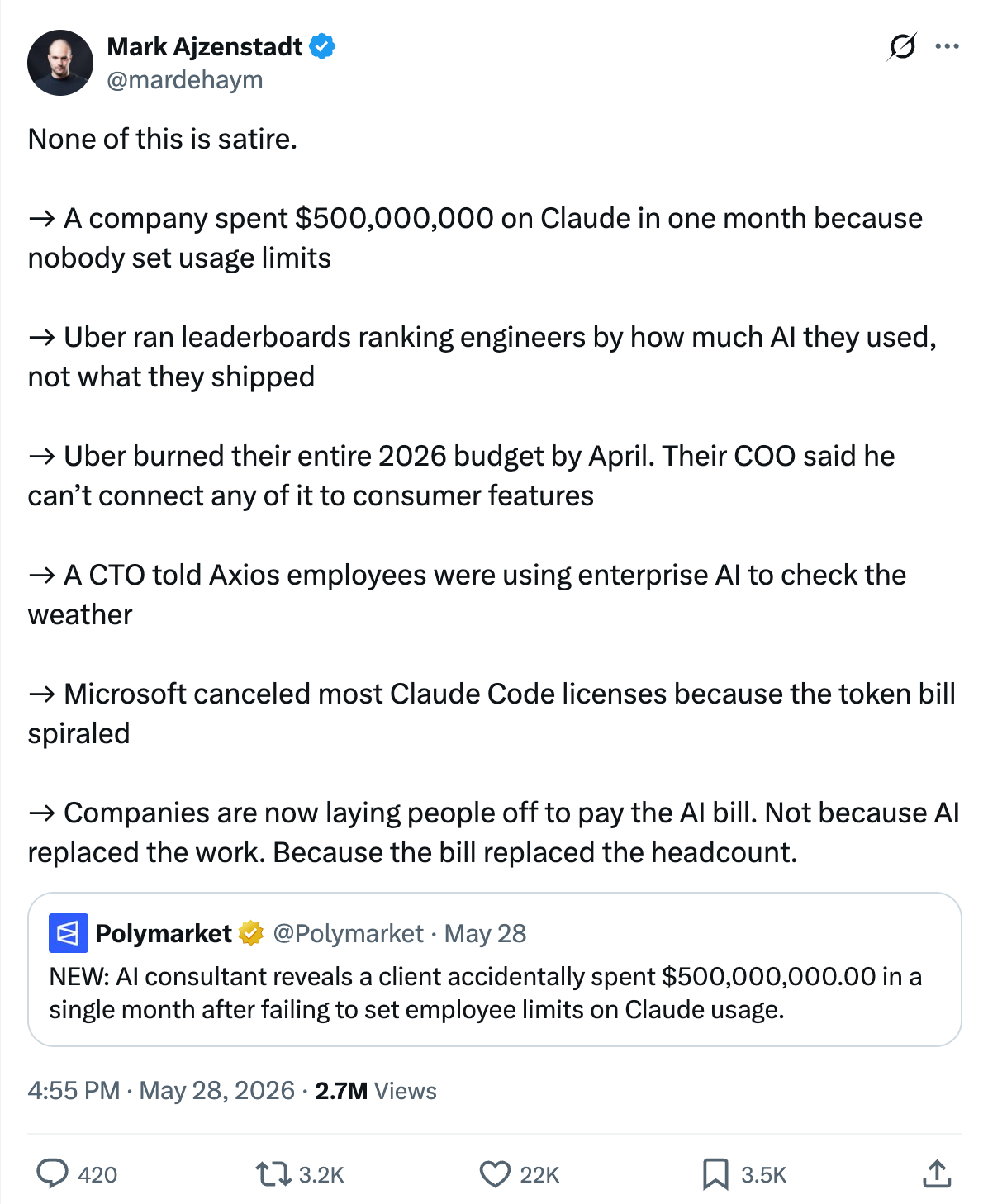
Observation #1: AI for software engineering is pretty awesome. AI for data sucks, despite being technically simpler than software engg.
Lack of shared context is the consistent failure mode
Pattern 1: Consumers of work do not have the subject matter expertise to verify correctness
The operations team wants to use AI to ad-hoc query data to make better/faster decisions. But when they use the AI and get an output, they don't know if it's right or wrong. They need the data-teams expertise. However, the data team doesn't have the time to keep prepping all the required context and package it up as "all their expertise ever" upfront, because the needs are ad-hoc.
The solution is to capture the missing context between the operator and the data expert and then feed it back into future runs.
Examples:
open-rate.md and open-rate.json - context
# Open rate (individual context)
<metric and how to calculate context from open-rate.json>
email-performance.md - shared context
# Analyzing email performance with open rates (shared context)
When analyzing email performance calculate [open rates](./open-rates.md) within that segment: (segment opens / segment sends).
Do not calculate what percentage of overall opens came from that segment - that conflates audience composition with subject line effectiveness.
A segment can have 50% of total opens but only a 5% open rate if it comprises most of your sends, or 10% of total opens but a 40% open rate if it's a small, highly engaged segment.
Example:
* Email A sent to 1000 technical personas, 120 opened → 12% technical open rate
* Email B sent to 1000 technical personas, 180 opened → 18% technical open rate
* Email B performs better for technical audiences regardless of what percentage of total opens came
Pattern 2: Producers of work do not have business acumen to know what to do, or judge goodness of work
The engineering team needs input from the product team or the customer to understand their needs and allocate their AI token resources. Also, once the work is done, they need the product team or the customer to comment on how good the work done was so that they have feedback for the next cycle of work.
The solution is to capture the missing context between the buyer of the product and the builder of the product and then make that context available for future runs.
Thinking about this from the "Asymmetry of Verification" perspective, I think of shared context as the cheap verification, or upfront research, in domains where verification is otherwise expensive because the verifier lives in someone else's head.
Even for Sam Altman's hypothetical one-person billion dollar company, customers are critical. Otherwise their impact is limited to increasing the earth's temperature (like when SPJ said pure functions without effects only heating up your CPU...still cracks me up).
Presence of shared context is the alpha
Shared context is a singular asset in that it compounds very quickly.
Shared context closes the loop on work done by AI because it provides a verification and improvement loop for AI users. If we had enough closed loops, then we would move on to find more loops or higher order loops.
Suppose we unlocked the shared context required to query data accurately, the immediate and organic next step would be to move a level up:
Query data accurate →
Interpret data results →
Take an action →
Make multiple testable hypotheses →
Run A/B tests
The obvious flip-side of this compounding effect is that the gap between AI native competitors to a legacy company will keep increasing. A team or organization that hasn't achieved the first can't even fathom that the fourth is possible and not some AI slop.
What should your shared context metric look like?
I define shared context as the skills + knowledge + semantic layer required to provide work input, to do work, and to know if the work done is good enough.
All this context can be captured as some variation of the markdown + json that needs to be fed to a coding agent that's securely connected to the right data and tools.
Consider the simple metric: "daily updates to shared context".
Yes, this is goodhart-able; please consider it for illustrative purposes. A real metric would have to weigh context by its usage, not just by its daily updates and so on.
Trend
Verdict
What it means
Trending down
Not good
You had an initial heroic effort of putting together shared skills in a repo. It's now most likely unused and rotting. Given the pace of business and AI technology, it is unlikely that the repo is not being continuously updated if it is being used.
Trending flat
Ok
You are actively maintaining your shared skills repo. This means AI is being used to drive some business outcome because it's generating valuable context with every run that is being fed back.
Trending upwards
Great
Congratulations, you might be truly AI native! Not only are you actively driving things with AI and keeping its context up to date regularly, but you're also continuously doing new things with AI that come with their own steady state of context maintenance.
Now that tokenmaxxing is dead – long live contextmaxxing.